
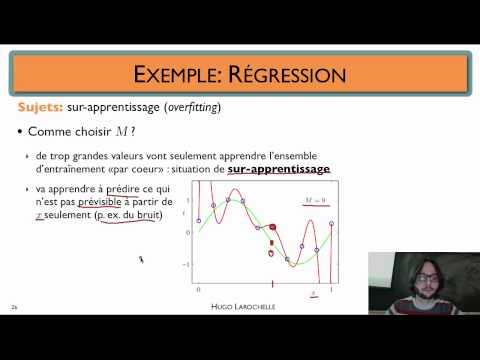
Le surapprentissage, également connu sous le nom de sur-ajustement, est un phénomène qui se produit lorsque les modèles d’apprentissage automatique sont trop bien adaptés aux données d’entraînement. En d’autres termes, le modèle apprend les détails spécifiques des données d’entraînement, y compris le bruit et les anomalies, au point qu’il perd sa capacité à généraliser à de nouvelles données. Cela conduit à une performance médiocre sur des données non vues, ce qui rend le modèle inefficace dans des scénarios du monde réel.
Le surapprentissage est un problème courant dans l’apprentissage automatique, et il peut se produire dans une variété de contextes, notamment la classification, la régression et le regroupement. Il est particulièrement problématique dans les situations où les données d’entraînement sont limitées ou bruyantes, ou lorsque le modèle est trop complexe par rapport à la quantité de données disponibles.
Pour comprendre le surapprentissage, il est utile de considérer l’analogie d’un élève qui apprend par cœur un texte pour un examen; L’élève peut être capable de réciter le texte mot à mot, mais il ne comprend pas nécessairement le sens sous-jacent du texte. De même, un modèle d’apprentissage automatique qui est sur-entraîné peut être capable de prédire avec précision les données d’entraînement, mais il ne peut pas généraliser à de nouvelles données. Cela est dû au fait que le modèle a appris les détails spécifiques des données d’entraînement, y compris le bruit et les anomalies, au point qu’il a perdu sa capacité à extraire les caractéristiques générales.
Le surapprentissage est un problème important car il peut conduire à des modèles d’apprentissage automatique peu fiables et inefficaces. Il est donc crucial de comprendre les causes du surapprentissage et de développer des stratégies pour l’atténuer.
Causes du surapprentissage
Le surapprentissage peut être causé par un certain nombre de facteurs, notamment ⁚
- Données d’entraînement limitées ⁚ Lorsque les données d’entraînement sont limitées, le modèle peut apprendre les détails spécifiques des données d’entraînement, y compris le bruit et les anomalies, au point qu’il perd sa capacité à généraliser à de nouvelles données.
- Données d’entraînement bruyantes ⁚ Les données d’entraînement bruyantes peuvent introduire des erreurs dans le modèle, ce qui peut conduire à un surapprentissage.
- Modèle trop complexe ⁚ Un modèle trop complexe peut avoir une capacité élevée, ce qui signifie qu’il peut apprendre une grande variété de fonctions. Cependant, cela peut également conduire à un surapprentissage, car le modèle peut apprendre les détails spécifiques des données d’entraînement, y compris le bruit et les anomalies.
Conséquences du surapprentissage
Le surapprentissage peut avoir un certain nombre de conséquences négatives, notamment ⁚
- Performance médiocre sur des données non vues ⁚ Un modèle sur-entraîné peut avoir une performance médiocre sur des données non vues, car il a appris les détails spécifiques des données d’entraînement, y compris le bruit et les anomalies.
- Modèle peu fiable ⁚ Un modèle sur-entraîné peut être peu fiable, car il peut ne pas être capable de prédire avec précision les données non vues.
- Difficulté à interpréter le modèle ⁚ Un modèle sur-entraîné peut être difficile à interpréter, car il peut avoir appris des relations complexes et non intuitives entre les données d’entrée et de sortie.
Stratégies pour atténuer le surapprentissage
Il existe un certain nombre de stratégies pour atténuer le surapprentissage, notamment ⁚
- Réduction de la complexité du modèle ⁚ Réduire la complexité du modèle peut aider à prévenir le surapprentissage en limitant la capacité du modèle à apprendre les détails spécifiques des données d’entraînement.
- Réduction de la taille du modèle ⁚ Réduire la taille du modèle peut aider à prévenir le surapprentissage en limitant le nombre de paramètres du modèle.
- Régularisation ⁚ La régularisation est une technique qui pénalise les modèles complexes, ce qui les encourage à généraliser mieux aux nouvelles données.
- Dropout ⁚ Le dropout est une technique qui consiste à supprimer aléatoirement des nœuds du réseau neuronal pendant l’entraînement, ce qui permet de prévenir le surapprentissage en empêchant le modèle de dépendre trop d’un seul nœud.
- Arrêt anticipé ⁚ L’arrêt anticipé est une technique qui consiste à arrêter l’entraînement du modèle avant qu’il ne converge complètement, ce qui permet de prévenir le surapprentissage en empêchant le modèle de sur-apprendre les données d’entraînement.
- Validation croisée ⁚ La validation croisée est une technique qui consiste à diviser les données d’entraînement en plusieurs ensembles et à utiliser chaque ensemble pour valider le modèle, ce qui permet de prévenir le surapprentissage en évaluant la performance du modèle sur des données non vues.
- Méthodes d’ensemble ⁚ Les méthodes d’ensemble sont des techniques qui combinent plusieurs modèles pour améliorer les performances et réduire le surapprentissage.
Le surapprentissage et la mémoire humaine
Le surapprentissage est un phénomène qui se produit non seulement dans les modèles d’apprentissage automatique, mais aussi dans la mémoire humaine. En effet, la mémoire humaine est un système complexe qui est sujet à des erreurs et à des biais. Le surapprentissage peut se produire lorsque nous nous concentrons trop sur les détails spécifiques d’un événement ou d’une information, au point que nous perdons notre capacité à généraliser à de nouvelles situations;
Par exemple, si nous apprenons une liste de mots par cœur, nous pouvons être capables de réciter la liste mot à mot, mais nous ne pouvons pas nécessairement nous souvenir du sens des mots ou de leur relation les uns avec les autres. Cela est dû au fait que nous avons appris les détails spécifiques des mots, mais nous n’avons pas compris le sens sous-jacent. De même, si nous lisons un livre sur un sujet particulier, nous pouvons nous souvenir de détails spécifiques du livre, mais nous pouvons ne pas être capables d’appliquer les connaissances du livre à de nouvelles situations.
Le surapprentissage peut également se produire lorsque nous sommes exposés à des informations biaisées ou erronées. Par exemple, si nous lisons un article de presse qui présente un point de vue biaisé, nous pouvons être amenés à croire que ce point de vue est la vérité, même si ce n’est pas le cas. Cela est dû au fait que nous avons appris les détails spécifiques de l’article, mais nous n’avons pas pris en compte les autres points de vue possibles.
Le surapprentissage peut avoir un certain nombre de conséquences négatives sur la mémoire humaine, notamment ⁚
- Difficulté à généraliser à de nouvelles situations ⁚ Le surapprentissage peut rendre difficile la généralisation à de nouvelles situations, car nous nous concentrons trop sur les détails spécifiques d’un événement ou d’une information.
- Biais cognitifs ⁚ Le surapprentissage peut contribuer aux biais cognitifs, car nous pouvons être amenés à croire que nos propres expériences et connaissances sont les seules vraies.
- Difficulté à apprendre de nouvelles informations ⁚ Le surapprentissage peut rendre difficile l’apprentissage de nouvelles informations, car nous pouvons être réticents à remettre en question nos connaissances existantes.
Stratégies pour atténuer le surapprentissage dans la mémoire humaine
Il existe un certain nombre de stratégies pour atténuer le surapprentissage dans la mémoire humaine, notamment ⁚
- Être conscient des biais cognitifs ⁚ Être conscient des biais cognitifs peut nous aider à identifier les situations où nous pouvons être sujets au surapprentissage.
- Chercher des points de vue différents ⁚ Chercher des points de vue différents peut nous aider à remettre en question nos propres connaissances et à éviter d’être trop concentrés sur un seul point de vue.
- Être ouvert à de nouvelles informations ⁚ Être ouvert à de nouvelles informations peut nous aider à apprendre de nouvelles choses et à éviter d’être trop attaché à nos connaissances existantes.
- Se concentrer sur la compréhension ⁚ Se concentrer sur la compréhension plutôt que sur la mémorisation peut nous aider à apprendre les concepts sous-jacents et à généraliser mieux à de nouvelles situations.
Conclusion
Le surapprentissage est un phénomène qui se produit à la fois dans les modèles d’apprentissage automatique et dans la mémoire humaine. Il est important de comprendre les causes du surapprentissage et de développer des stratégies pour l’atténuer, car il peut avoir un certain nombre de conséquences négatives. En étant conscients des biais cognitifs, en cherchant des points de vue différents et en étant ouverts à de nouvelles informations, nous pouvons améliorer notre capacité à apprendre et à généraliser à de nouvelles situations.

J’apprécie la clarté de l’article et sa capacité à expliquer des concepts complexes de manière accessible. La section sur les causes du surapprentissage est particulièrement utile, car elle met en évidence les différents facteurs qui peuvent contribuer à ce phénomène.
L’article est une introduction solide au surapprentissage, un concept crucial en apprentissage automatique. La clarté de l’écriture et les exemples pertinents facilitent la compréhension du sujet.
L’article est bien écrit et facile à comprendre. La description des causes du surapprentissage est particulièrement instructive, et permet de mieux appréhender les défis liés à la construction de modèles d’apprentissage automatique robustes.
L’article est un bon point de départ pour comprendre le surapprentissage. La description des causes du surapprentissage est particulièrement instructive, et permet de mieux appréhender les défis liés à la construction de modèles d’apprentissage automatique robustes.
L’article met en lumière l’importance de comprendre le surapprentissage pour construire des modèles d’apprentissage automatique performants. La section sur les causes du surapprentissage est bien structurée et fournit des informations précieuses.
Cet article offre une introduction claire et concise au surapprentissage, un concept fondamental en apprentissage automatique. L’analogie avec l’élève qui apprend par cœur est particulièrement pertinente et permet de saisir facilement le problème. La description des causes du surapprentissage est également complète et informative.
L’article est bien structuré et fournit une introduction claire et concise au surapprentissage. La section sur les causes du surapprentissage est particulièrement utile, car elle met en évidence les différents facteurs qui peuvent contribuer à ce phénomène.
L’article aborde de manière efficace le problème du surapprentissage, en soulignant son impact sur la fiabilité des modèles d’apprentissage automatique. J’aurais aimé trouver une section plus approfondie sur les stratégies d’atténuation du surapprentissage, mais l’article reste une excellente introduction au sujet.
L’article offre une vue d’ensemble complète du surapprentissage, en couvrant ses causes et ses conséquences. La section sur les stratégies d’atténuation du surapprentissage aurait pu être plus détaillée, mais l’article reste une ressource précieuse pour les débutants en apprentissage automatique.